Write Better Build Scripts
We need simple and efficient build automation both locally, when developing, and in CI pipelines. The use case is slightly different but the goals are the same — scripts need to be simple to write, simple to read and understand, and they need to be repeatable, but we don’t want to repeat unnecessary work.
It’s a challenging problem, with solutions that date back decades.
One of the oldest tools is make, which is still extremely popular (and for good reason). However, writing a Makefile can get complex quite quickly. Its arcane syntax is challenging, making it hard to write, and, in my opinion, even harder to read. And often, the best feature of make is not even used — the ability to only rebuild a target if it’s inputs have changed (i.e. have a later modification time). Most people add .PHONY to targets and just use make as a task runner. This is because it has a built in mechanism for building a Directed Acyclic Graph of dependencies, which is useful, and because the original use case (building C or C++ projects) is not what most people are doing these days (the enlightened are using Rust instead). :-)
There are now many tools that have been inspired by make, including just, and cargo-make. They attempt to improve on the syntax of make and are useful if you want a powerful task runner (and don’t care about the change detection).
At the other end of the spectrum, we have tools like Bazel and Buck. These are great tools, that do exactly what we want (although they can be quite complex to configure). So why don’t we use them instead? I think it’s because they need you to go all in. If you want to use either tool, you have to use it everywhere — every dependency needs to be tracked and controlled by the tool. This can work well in some ecosystems, e.g. Java. Not so well for others, e.g. Rust. This is because modern languages typically have their own highly capable toolchains (Rust has Cargo, for instance), and using Bazel, for example, on a Rust project means that you need to stop using Cargo (which is simple and mainstream) and use Bazel instead (which is complex and less widely used).
So is there something in the middle?
I really just need 3 things:
- a powerful scripting language that everyone knows (i.e. not an esoteric DSL), but one that makes it easy to orchestrate shell commands
- for local development, the ability to describe inputs and detect if they have changed since I last built
- for CI pipelines, a way to track newly changed dependencies in a monorepo, and create a build schedule
That’s really it.
The UNIX philosophy is all about small, sharp tools that do one thing and do it well. So, instead of trying to find a single tool that does all three of those things, why not choose 3 tools and combine them in a flexible way to achieve the overall goal?
Reluctant as I am to suggest it, the answer to the first need is probably JavaScript. It’s by far the most widely known scripting language. Arguably, you shouldn’t use a Turing-complete language for this job, instead preferring a declarative, rules-based, DSL. But I think JavaScript’s universality is too important to ignore, and it’s really useful to be able to easily manipulate configuration data when building software. But what about it being easy to orchestrate shell commands? This is where zx comes into play, making it incredibly easy to orchestrate shell commands from within JavaScript. We’ll dig into it shortly, but in a nutshell, I’ve been blown away by how simple, yet powerful, it is for this job.
Secondly, if I’m rebuilding over and over again on my laptop, I need a tool to describe my inputs and detect if they have changed. This is really quite simple. Everyone uses git now (thankfully) and so describing inputs should be as simple as “every file, under these directories, that is tracked by git”. Detecting changes is as simple as “compute a hash of all these inputs, which I can compare with the hash from the last successful build”. Fortunately, there is a tool that does precisely that — it’s called dirsh — and it’s written in Rust! (Have you worked out that I love Rust, yet?). Anyway, ignoring its unfortunate name, dirsh is fast and simple. We’ll look at how to use this shortly.
Finally, we need a way for my CI pipeline to know what it has to build and in which order. It’s becoming more and more popular to use a monorepo, and I highly recommend doing so as a way to make it easier to build reliable software. In a monorepo, most of your immediate dependencies are in the same repository. You can commit changes, atomically, across your whole codebase. Versioning problems evaporate. Stability and reliability become much easier to achieve. If you have a monorepo, and you probably should, monobuild, written by my esteemed colleague, Viktor Charypar, is is an incredibly useful tool that allows you to graph your dependencies and schedule builds based on what has changed in the current branch (it’s also being rewritten in rust, so will become even better). Monobuild can help us create efficient build schedules and simple pipelines — we’ll look at how to do that below.
Using zx
First install zx:
npm install --global zx
Then create a file (e.g. touch make.mjs), make it executable (e.g. chmod +x make.mjs), and add a shebang at the top:
#!/usr/bin/env zx
Calling into the shell is as simple as this:
await $`pwd`;
Check this out:

This is the first run (because the hash changed, we run the build):
./make.mjs --build
----
Building actor...
{
previous: 'P5FPQUJTDYU4EWWQMA7MXHBCMM',
current: 'J62CYREXEFFEM45UKTTJ5Q4XQY'
}
$ cargo build --release
Compiling wasmcloud-graphql-interface v0.1.0 (/Users/stuartharris/src/wasmCloud/wasmcloud-graphql-provider/interface/rust)
Compiling pass_through v0.1.0 (/Users/stuartharris/src/wasmCloud/wasmcloud-graphql-provider/actor)
Finished release [optimized] target(s) in 4.87s
$ wash claims sign target/wasm32-unknown-unknown/release/pass_through.wasm --cap $'stuart-harris:graphql-provider' --cap $'wasmcloud:builtin:logging' --cap $'wasmcloud:httpserver' --name pass_through --ver 0.1.0 --rev 0 --destination build/pass_through_s.wasm
Successfully signed build/pass_through_s.wasm with capabilities: stuart-harris:graphql-provider,wasmcloud:builtin:logging,wasmcloud:httpserver
$ wash claims inspect build/pass_through_s.wasm
pass_through - Module
Account ADHSOZVDL2ZLVX5UXBSGKNLN5UOMU5MPDHN3UQTQ6DYT5TFZ7HGLGIUP
Module MA5PVZ6QNJK5TELQHPQGICJJ2EFVH7YDVXKF2NCUTYGSVVHUCEOL5UW6
Expires never
Can Be Used immediately
Version 0.1.0 (0)
Call Alias (Not set)
Capabilities
stuart-harris:graphql-provider
wasmcloud:builtin:logging
HTTP Server
Tags
None
This is the second run (because the hash is the same, we can skip the build):
./make.mjs --build
----
Building actor...
{
previous: 'J62CYREXEFFEM45UKTTJ5Q4XQY',
current: 'J62CYREXEFFEM45UKTTJ5Q4XQY'
}
$ wash claims inspect build/pass_through_s.wasm
pass_through - Module
Account ADHSOZVDL2ZLVX5UXBSGKNLN5UOMU5MPDHN3UQTQ6DYT5TFZ7HGLGIUP
Module MA5PVZ6QNJK5TELQHPQGICJJ2EFVH7YDVXKF2NCUTYGSVVHUCEOL5UW6
Expires never
Can Be Used immediately
Version 0.1.0 (0)
Call Alias (Not set)
Capabilities
stuart-harris:graphql-provider
wasmcloud:builtin:logging
HTTP Server
Tags
None
Also, parsing JSON is a doddle:
const metadata = JSON.parse(
await $`cargo metadata --no-deps --format-version 1`
);
const projectName = metadata.packages[0].name;
Anyway, you get the idea. Very powerful.
Using dirsh
First install dirsh:
cargo install dirsh
Calling dirsh, on its own, will cause it to walk down recursively from the current directory (honouring your .gitignore files, and its own .hashignore if you need it), feeding file contents (with their modification times and modes) into the digest, and then write the digest to stdout:
dirsh
produces something like this:
JLAU7VF3L5IXQ5L66AXEILCHE4
This is how I call it from zx (passing it an array on input directories):
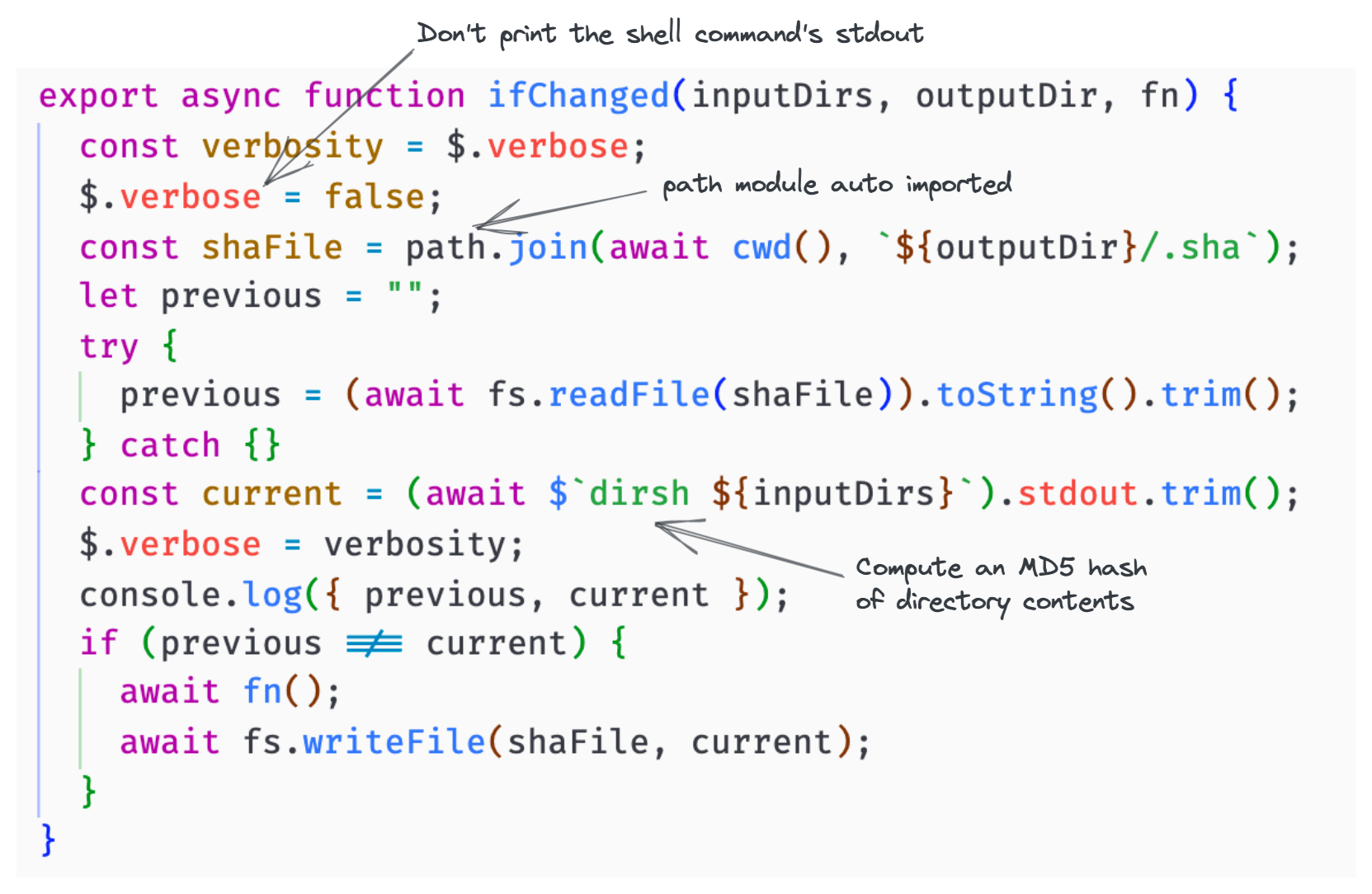
Pretty cool.
Using monobuild
First install monobuild:
cargo install --git https://github.com/charypar/monobuild
Add some files, named Dependencies, into your monorepo. I’ve made interface a strong dependency of both actor and provider — that’s the ! — because it has some codegen that needs to run:
bat */Dependencies
───────┬──────────────────────────────────────────
│ File: actor/Dependencies
───────┼──────────────────────────────────────────
1 │ !interface
───────┴──────────────────────────────────────────
───────┬──────────────────────────────────────────
│ File: interface/Dependencies <EMPTY>
───────┴──────────────────────────────────────────
───────┬──────────────────────────────────────────
│ File: provider/Dependencies
───────┼──────────────────────────────────────────
1 │ !interface
───────┴──────────────────────────────────────────
Then get a build schedule based on what has changed (in git) since you cut your branch (or since the HEAD^1 commit, if you’re on main):
monobuild diff --dot
If only interface had changed, this is what the schedule would look like. Note that because actor and provider both depend on interface, and interface has changed, we need to rebuild both:
digraph schedule {
randir="LR"
node [shape=box]
"actor" -> "interface"
"interface"
"provider" -> "interface"
}
If only actor had changed, this would be the schedule:
digraph schedule {
randir="LR"
node [shape=box]
"actor"
}
Then all we have to do in our CI pipeline is call the relevant zx scripts according to the supplied graph. This is easier to parse if you don’t specify --dot, for example:
monobuild diff
produces an adjacency list:
actor: interface
interface:
provider: interface, another-dep
We can use this graph to decide in the CI pipeline what can be done in parallel and what needs to be done in series. At it’s simplest, creating an ordered list of dependencies to build would require parsing the adjacency list, and using a depth-first algorithm on the graph. Here’s an example that calls ./make.mjs in each of the dependencies in the correct order (but in series):
#!/usr/bin/env zx
$.verbose = false;
const schedule = getSchedule(parse((await $`monobuild diff`).stdout));
$.verbose = true;
for (const dep of schedule) {
cd(dep);
await $`./make.mjs ${getArgs()}`;
}
function parse(diff) {
return diff.split("\n").reduce((acc, line) => {
const [vertex, adjacents] = line.split(":");
if (vertex) {
acc[vertex] = adjacents
.split(",")
.map((a) => a.trim())
.filter((a) => a);
}
return acc;
}, {});
}
function getSchedule(adjacencyList) {
return Object.keys(adjacencyList)
.map((entryPoint) => {
const result = [];
const visited = {};
(function dfs(vertex) {
if (!vertex) return null;
visited[vertex] = true;
result.push(vertex);
adjacencyList[vertex].forEach((neighbour) => {
if (!visited[neighbour]) {
return dfs(neighbour);
}
});
})(entryPoint);
return result.reverse();
}) // depth-first
.flatMap((list) => list) // flatten
.filter((vertex, index, self) => self.indexOf(vertex) === index); // unique
}
function getArgs() {
return Object.keys(argv)
.filter((k) => k !== "_")
.flatMap((a) => [`--${a}`, argv[a]]);
}
Wow, that’s more code than we thought. But it’s good that we can even do it — imagine doing something like that in a Makefile.
Interestingly, even if we don’t flatten our paths, and remove duplicates, we still wouldn’t be doing extra work because of dirsh.
In a real world, we’d wan’t to project the graph onto a set of CI tasks that run in parallel where they can and series where they can’t. Watch this space :-).
TLDR
Build scripts need more flexibility than most declarative build configurations allow for, and, whilst I would always opt for declarative over imperative, I think the flexibility and widespread use of JavaScript gives us superpowers when building software. Especially when we hash our inputs, so that we don’t repeat unnecessary work. Coupled with git-based change detection and dependency graphing in our CI pipelines, we have everything we need for simple, easy-to-grok, repeatable builds.
All the code examples can be found in this repo, which is a GraphQL provider for wasmCloud that exposes a postgres database as a GraphQL API.
LMK what you think!